Une application sur le taux de remplissage des parkings voiture de Nantes
Publié le 20/03/2020
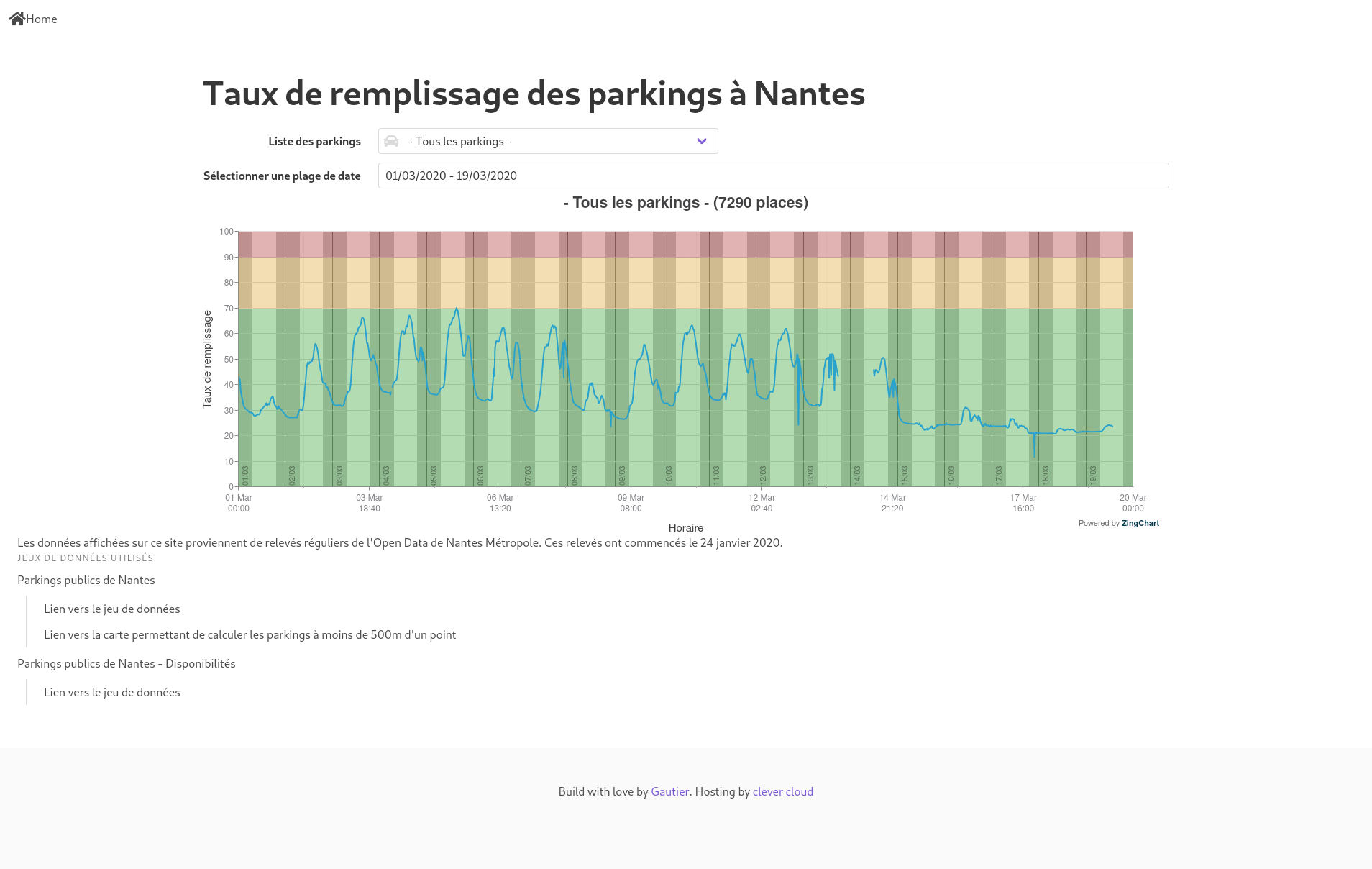
On pourrait presque résumer l’origine de ce projet par "Ils se demandaient s’il y avait une appli sur les parkings voiture de Nantes alors il l’a fait.". C’est légèrement mentir mais on va faire comme si.
En fait tout est partie d’un tweet ou d’un ensemble de tweets de la cyclosphère nantaise en décembre 2019. Je ne les retrouve pas mais dans la conversation il y avait de mémoire Sam Nantes. On y parlait de savoir pourquoi une zone piétonne était devenue un parking temporaire pour faire les courses de noël alors qu’il y avait de la place dans les parkings de la ville.
Comme tout postulat c’est simple de dire que les parkings voiture sont vides. Cela nécessite d’être confirmé ou infirmé. Et pour cela il faut récupérer des données régulièrement, les stocker et surtout les exploiter.
Superbe idée mais pour ça il faut du temps et les compétences. L’idée m’a donc travaillé quelques temps et finalement profitant d’une fin de mission je me suis lancé sur le sujet courant janvier.
Cet article présente une partie des données et framework sur lesquels je me suis basé pour développer l’application. J’y ajoute mon ressenti des technologies utilisées.
Les données, le nerf de la guerre
Bien entendu on va commencer par la base, il nous faut des données. Puisque la ville de Nantes propose de l’open data, on va naviguer un peu sur le site dédié de Nantes Métropôle.
Alors c’est presque du pain béni car il y a un jeu de données en temps réel sur le sujet : Parkings publics de Nantes - Disponibilités. Alors quand on parle de parking à Nantes, on oublie les places pour les vélos, c’est orienté voiture uniquement. Je n’ai d’ailleurs pas trouvé de jeux de données sur d’éventuels parking vélos. Ça me plairait bien.
Dans notre cas l’application sera orienté parking voiture donc c’est impeccable.
Récupération des données
Il est possible de récupérer les données de plusieurs manières. Soit un export au format CSV, JSON ou Excel. Soit via une API.
Dans notre cas, il est plus pertinent d’utiliser l’API.
Comme j’aime être à la pointe, j’ai la version 2 qui est en bêta depuis quelques temps déjà.
Elle est disponible via ce lien et la liste des données est à cette adresse.
La trame JSON complète est assez verbeuse. Voici la partie utile d’un enregistrement.
{
"id": "2b9b92281980b49b293cf0edb83efd3f697b6faf",
"timestamp": "2020-03-20T09:14:00Z",
"size": 77,
"fields": {
"grp_complet": 10, (1)
"grp_identifiant": "001",
"grp_horodatage": "2020-03-20T09:11:46+00:00", (2)
"grp_disponible": 374, (3)
"idobj": "4320", (4)
"grp_nom": "Feydeau", (5)
"grp_statut": 5, (6)
"grp_exploitation": 499, (7)
"grp_pri_aut": null
}
}| 1 | Nombre de places restantes à partir duquel le parking affiche officiellement complet : ne servira pas |
| 2 | Horaire de l’information : ne servira pas, je prendrais l’heure à laquelle j’effectue le relevé |
| 3 | Nombre de places disponibles |
| 4 | L’identifiant de l’équipement public |
| 5 | Nom de l’équipement |
| 6 | Code donnant le statut du groupe : ne servira pas |
| 7 | Nombre de places ouvertes aux clients horaires |
Traitement de la données
Toutes les 10 minutes, je fais un appel à l’API et je récupère les résultats. Je sauvegarde le tout dans la base de données. Ensuite il ne reste plus qu’à l’exploiter et faire de "beaux" graphiques. Pour cela ce sera une petite application JS qui récupère les données via ma propre API et qui affiche un graphique.
On en parle dans la suite de l’article.
Du Quarkus et du Vue.js
Cette partie explique simplement les choix techniques qui ont été fait sur l’application. Certains choix ont parfois eu des conséquences et je compte écrire un post-mortem sur la perte de données que j’ai eu la semaine dernière dans un autre article.
Une application Quarkus
Quoi de mieux qu’un petit projet pour tester plus amplement une technologie ? Pour moi rien et je pense que d’autres se sont dit la même chose. Je n’ai pas la prétention de vous apprendre à utiliser Quarkus. Pour cette partie je préfère vous renvoyer vers les guides officiels ainsi que le super workshop d’Antonio Goncalves, Clément Escoffier et Emmanuel Bernard.
Un peu de panache pour la gestion de la donnée
Tout d’abord, j’ai choisi la couche de persistance. J’utilise une base de données PostgreSQL et j’ai décidé d’utiliser un ORM. Oui je sais c’est le mal pour certains. Et non ne vous inquiétez pas, je sais que le SQL pur a du bon. J’en fais toujours notamment dans ce projet.
Quarkus propose deux alternatives pour du hibernate.
Un mode standard qui correspond à ce que beaucoup d’applications JavaEE/JakartaEE font.
Un mode remplit de panache.
C’est ce dernier que j’ai décidé d’utiliser. Si vous êtes curieux de voir à quoi ça ressemble en vrai, voici le guide officiel.
Mes premières impressions sont vraiment bonnes.
J’aime beaucoup l’API fournit par hibernate-with-panache.
Elle est agréable à utiliser, l’extension par des méthodes dans l’entité ou la création de repository est simple.
Cette partie est très plaisante.
|
Petite anecdote lors de l’utilisation de cette bibliothèque. Vos entités vont étendre la classe Votre IDE va peut-être vous dire que vous pouvez remplacer les appels de méthode avec l’implémentation de la classe parente. Voir votre IDE est configuré pour effectuer ce remplacement pour vous. C’est une mauvaise idée car au runtime, cela ne fonctionne pas. Je me suis fait piéger lors de test sur Quarkus au mois de septembre 2019. |
Récupération des données à intervale régulier
Rien de bien compliqué pour récupérer des données à interval régulier. Si vous voulez lancer des tâches périodiques, l’extension quarkus-scheduler est faite pour vous.
Je n’ai pas exploré cette extension en détail.
J’ai un bean annoté par @ApplicationScoped avec une méthode annoté avec @Scheduled(cron = "0 0/10 * * * ?") et c’es tout.
Si vous avez besoin d’utiliser quartz, il y a une extension spécifique pour ça.
Côté appel de l’API open data de Nantes Métropôle, j’ai décidé de tester l’extension quarkus-rest-client. La partie rest-client provient de MicroProfile. Je ne connaissais pas et j’ai trouvé ça diablement efficace.
Une API simple
Au niveau de mon API pour mon application JS, je suis resté dans le très simple. J’aurais pu tester des routes Vert.x, envoyer les données au front via du push server, mais pour le moment ce n’est pas le cas.
Du JAX-RS avec RESTEasy et Jackson et c’est tout. Le guide de Quarkus à ce sujet est très clair.
Du Vue.js pour faire une seule page
Tout de suite ça envoit moins du rêve n’est ce pas ? Et pourtant c’est la réalité de l’application actuellement. À l’heure où j’écris cet article, j’ai clairement sorti un tank pour tuer une mouche. J’avais envie d’écrire du Vue.js donc c’est purement un choix dicté par l’envie et non pas le besoin.
Après le lancement de l’appplication et les premiers retours que j’ai eu, je sais que je continuerais à la faire évoluer. Le choix de Vue.js n’est peut être pas si mal même s’il reste pour le moment overkill.
Au niveau de l’application front, j’ai ajouté deux bibliothèques.
L’hébergement ? Du clever cloud of course
Quand il s’agit d’hébergement j’avoue apprécier la simplicité de l’hébergeur Nantais clever cloud. Un git push et ça part en prod ? Que demande le développeur !
Là encore je ne vais pas vous faire une explication complète de comment déployer une application Quarkus sur clever cloud. Dans un premier temps, je suis parti sur du Quarkus en mode JVM. Ayant déjà de l’expérience dessus, je n’ai pas eu de soucis. Vous pouvez regarder cette documentation pour savoir comment faire.
Par contre lorsque j’ai souhaité partir en mode graalvm, j’ai eu un peu plus de mal. Si comme moi cela vous intéresse, je ne peux que vous conseiller cet article de Nicolas Martignole.
Et ça coûte combien ?
Quand on parle d’hébergement d’une application, il y a forcément un coût. Que ce soit vous ou une autre personne qui paye, quelqu’un paye. Est ce cher ? Non.
J’ai commencé à utiliser la plateforme clever cloud le 24 janvier pour récupérer les données. A ce moment là j’ai utilisé :
-
Un add-on PostgreSQL DEV : 0,00€ / mois
-
Une instance
nanopour l’application : ~0,20€ / jour
Depuis pour le lancement officiel de l’application j’ai changé la base de données par une vrai instance.
-
Un add-on PostgreSQL XXS_SML : 5,25€ / mois
-
Toujours mon instance
nano: ~0,20€ / jour
Sur un an temps plein, on parle d’un hébergement à :
-
365 x 0,20€ + 12 x 5,25€ = 136,00€ / an
Alors oui ce petit projet a un coût, mais il ne faut pas oublier que derrière un service d’hébergement il y a des gens qui ont besoin de manger. Et puis clever cloud est nantais. Je fais donc fonctionner l’économie locale pour un projet local.
Une petite conclusion pour la route
On m’a fait la remarque que l’application n’était pas open source. En fait, je n’ai pas envie de faire du support spécifique ni valider des contributions. Ce projet est personnel même s’il a vocation à être utilisé par tout le monde.
A ce titre je n’exclus pas de le refaire dans d’autres technos de casser le code à l’intérieur pour tester des solutions techniques variées. C’est mon bac à sable privé et j’entends à ce qu’il le reste pour le moment.
Par contre ne vous inquiétez pas, l’application n’a pas vocation à disparaître, bien au contraire.
J’ai également envie de vous dire :
-
Faites-vous plaisir avec parkings.jabby-techs.fr.
-
Remontez-moi vos idées sur Twitter / mail (cf. pied de page)
-
Et si vous voulez participer financièrement à l’hébergement, Faites moi signe, je lancerais peut être un mode sponsoring.